
L’introduzione di async e await consente di scrivere codice asincrono, come se si trattasse di codice sincrono
Non sempre però l’utilizzo della Programmazione Asincrona con Async e Await viene utilizzata in maniera appropriata: è necessario seguire alcune linee guida per evitare di incappare in problemi non sempre di facili risoluzione.
Nei prossimi articoli tratteremo alcuni errori tipici dovuti all’utilizzo non proprio appropriato delle keyword async-await.
Gli utilizzatori di software negli ultimi anni sono diventati sempre più esigenti: il web ha imposto la realizzazione di applicazioni reattive, o meglio senza interruzioni durante il loro flusso di funzionamento. Anche le applicazioni desktop legacy hanno dovuto adattarsi evitando di fatto di “bloccarsi” durante il caricamento e l’elaborazione di grandi quantità di dati.
Esistono ancora numerose applicazioni che hanno comportamento del tutto rispettoso (in termini di risposta), ma che per problemi esterni (come il rallentamento della connessione o delle risorse di elaborazione del server) si bloccano in attesa di una risposta). Buona parte di questi problemi sono dovuti all’utilizzo di chiamate sincrone: viene effettuata la chiamata e solo quando viene terminata vengono eseguite le istruzioni successive.
Analizziamo ad esempio una pagina web, che utilizza diverse fonti dati esterne (ad esempio feed rss) per fare il rendering dell’html: le chiamate eseguite una di seguito all’altra risultano bloccanti per il flusso e potrebbero generare il render dell’intera pagina dopo parecchi secondi. La soluzione potrebbe essere quella di introdurre un meccanismo che consenta di scaricare i vari feed parallelamente, esegundo il render al termine di ciascun flusso parallelo. Questa soluzione permette all’utilizzatore finale di non dover aspettare per la fruizione dei dati.
Ovviamente è sempre da valutare il tipo di contesto in cui andiamo ad operare ma, al giorno d’oggi, scrivere codice sincrono può essere considerato obsoleto.
Struttura di un metodo asincrono
Un metodo asincrono si differenzia da un metodo tradizionale per:
- firma: il metodo utilizza la parola chiave async. La presenza di questa keyword consente l’utilizzo della parola chiave await all’interno del metodo. Ad esempio un medodo che restituiva un void diventerà async void
- nome: un metodo asincrono, per convenzione, dovrà avere il suffisso Async. Ad esempio il metodo sincrono GetResponse diventerà GetResponseAsync
- await: l’utilizzo di questa keyword viene anteposta alla chiamata del metodo asincrono
Ripropongo (ancora una volta!?!) una tipica chiamata asincrona, dove vengono evidenziati i tre punti precedenti:
private async void OnRequestDownload(object sender, RoutedEventArgs e)
{
var request = HttpWebRequest.Create(_requestedUri);
var response = await request.GetResponseAsync();
// process the response
}
A prima vista, potremmo non notare la differenza con l’equivalente sincrono: effettivamente fino all’esecuzione del metodo GetResponseAsync dell’oggetto request il flusso è esattamente lo stesso. Una volta effettuata la chiamata il flusso non viene però introdotto e continua la normale esecuzione: l’operazione di download prosegue nel frattempo in background. Una volta terminato il download, il flusso riprende esattamente dal punto in cui era stato avviato (dove è stata inserita la parola chiave await), e alla variabile response vengono assegnati i dati scaricati. Per noi è del tutto trasparente quello che avviene “sotto al motore”: il risultato della chiamata viene trasformato da Task<WebResponse> in WebResponse e viene assegnato alla variabile response. Il codice necessario per la gestione delle chiamate asincrone viene generato per noi in fase di compilazione, dal compilatore.
Perchè utilizzare chiamate asincrone nel web?
Le chiamate sincrone vengono gestite uno dopo l’altra da thread dedicati. Le richieste vengono infatti accodate e solo al termine della precedente può essere eseguita la successiva. Le singole richieste vengono gestite mediante un pool (finito!) di thread limitando quindi le richieste che possono essere gestite in parallelo. Se le richieste vengono gestite in maniera asincrona il thread viene rilasciato rendendolo disponibile nel pool e consentendo quindi l’evasione di altre richieste.
Rappresentiamo visivamente le chiamate sincone e quelle asincrone:
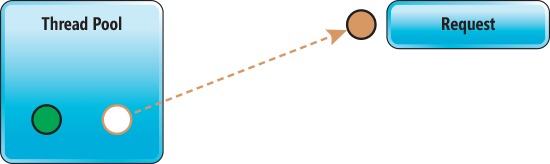
Esecuzione Sincrona: per essere evasa, una richiesta viene assegnata ad un thread disponibile all’interno del thread pool
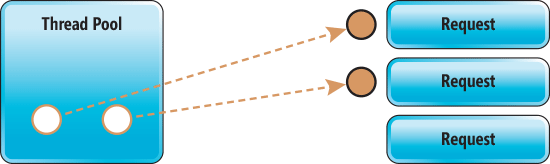
Esecuzione sincrona: i thread sono già impegnati nella gestione di due richieste. Il terzo thread è in attesa che uno dei due precedenti venga terminato
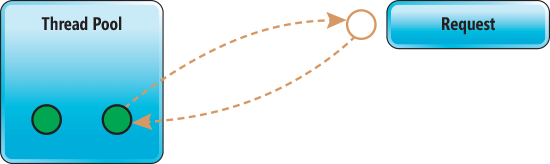
Esecuzione asincrona: viene associato un thread alla richiesta, ma viene successivamente rilasciato e reso quindi disponibile per l’evasione di altre richieste
Perchè non incrementare il numero dei thread del thread?
Siamo programmatori, non sistemisti! Sicuramente è una risposta valida. L’aggiunta di nuovi thread all’interno del thread pool richiede circa 1Mb di memoria per l’allocazione del proprio stack. Stiamo parlando di piccole quantità di memoria, ma per molti thread diventa sicuramente una componente non trascurabile. L’utilizzo di chiamate asincrone consente di riutilizzare la memoria per altri task durante l’esecuzione.
Il codice asincrono consente all’applicazione di utilizzare in modo ottimale il pool di thread.
Non è richiesto alcun thread per l’esecuzione di una funzione asincrona.
Async e Await consentono di rendere un’applicazione più scalabile a livello di server singolo, ma per sistemi più complessi potremmo avere la necessità di prendere in considerazione un modello differente di architettura distribuiti.
Disponendo, ad esempio, di un’architettura semplice in cui il nostro server web colloquia con un server database, l’utilizzo di chiamate asincrone risulta sicuramente un’ottima soluzione per quanto concerne l’ottimizzazione delle chiamate web, ma il vero collo di bottiglia è comunque rappresentato dall’accesso ai dati (read/write). Risulta quindi fondamentale un’analisi approfondita dell’archietttura per ottimizzare i comportamenti.